How do custom Encoder's work?
This article is part of a series.
- Part 1: What if I just copy-paste from the web?
- Part 2: How do you get messages to Swift directly?
- Part 3: Okay, but how about all the way up to the View?
- Part 4: How to do some basic file handling?
- Part 5: This Article
- Part 6: And what can I make a custom Encoder do?
- Part 7: Wait, how do I scan text again?
- Part 8: Date Parsing. Nose wrinkle.
- Part 9: What would be a very simple working Decoder?
So if I’m going to save the Line data as a file in the AppGroup storage area, what’s going to be in that file? The current bespoke String->Line/Line->String transformations have a lot of vulnerabilities. Given that we’re also working with JavaScript JSON would make a lot of sense. I quickly added JSON to the SimplePersist library, but realized that default JSONEncoder encodes whole objects only. This works well if transmitting the JSON over a network with the idea of checking that the whole object was received. It’s less ideal for data storage in a file where appending new items to the end without loading all of the data into memory would be useful. For the current very small amount of text data that would actually be fine, but I’ve been meaning to learn how to write custom Encoders and Decoders for awhile now. Here’s the excuse!
I used a handful of examples to guide my process:
- Solid Tutorial: objc.io Swift Talk # 348: Routing with Codable – Encoding
- StackOverflow 45169254: Custom Swift Encoder/Decoder for the Strings Resource Format
- JSONEncoder from 5.10
- JSONENcoder in FoundationEssentials
- Swift-OpenAPI URI Encoder
- StructuredFieldValues from Swift HTTP Structured Headers
- Swift Package Manager PlainTextEncoder Encoder only. Output direct to an OutputStream.
- ETA: CoreOffice/XMLCoder (see epilogue)
The Encodable side of the Codable ecosystem essentially boils down to Encodable conforming items have the potential to offer up a <CodingKey, Any> dictionary out of themselves and the intrepid Swift developer can then use the hooks provided by an Encoder conforming type to place that information in a data structure of their own making. Depending on the nature of that data structure an additional serialization step to spin the information into the desired final output format may be required.
Two different approaches emerge at this point. The first and simpler does most of the serialization work in the first pass of the encoder so the “data structure” is a thin veil over the desired final output. This approach gets used when the input data will be simple or the the Encoder itself doesn’t allow for much customization. The encoder can just return it’s data store practically as is when done. It could look something like:
//-------------------------------- PSUEDO CODE ---------------------------------
struct PublicEncoderType {
func encode(value:Encodable) -> String {
encoder = _PrivateEncoderType(data:myData())
value.encode(to: encoder)
return encoder.value
}
}
//Sometimes inside the above class, sometimes not.
struct _PrivateEncoderType:Encoder {
var data = MyDataType
var value:String {
data.storage
}
//...other things
}
//Sometimes inside one of the above classes, sometimes not.
class MyDataType {
var storage:String
func append<T>(value:T, forKey key:CodingKey?) {
storage.append(delimiter)
if let key {
storage.append(key.stringValue)
storage.append(":")
}
storage.append("\(value)")
}
//etc
}
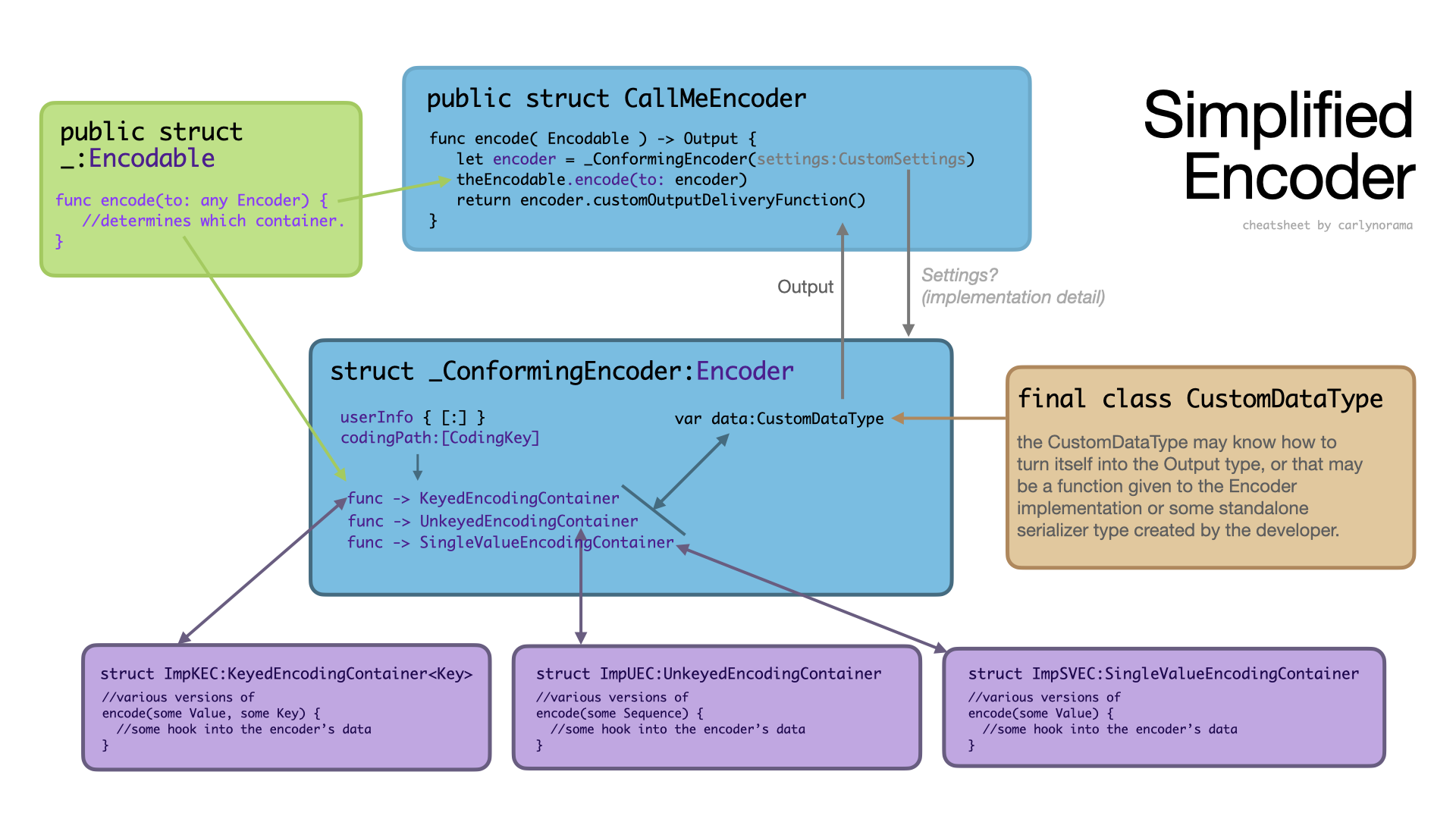
This is along the lines of what’s seen in the StackOverflow example and the SwiftTalk example.
In that StackOverflow example Paulo Mattos embeds the storage type into the Encoder. It handles its own updating with an encode function. He does not show a Decoder.
fileprivate struct StringsEncoding: Encoder {
fileprivate final class Data {
private(set) var strings: [String: String] = [:]
func encode(key codingKey: [CodingKey], value: String) {
let key = codingKey.map { $0.stringValue }.joined(separator: ".")
strings[key] = value
}
}
//...
}
In the SwiftTalk example the storage type stands alone as it gets used for both encoding and decoding. It’s just a dumb storage box being used for its reference-typeyness. Other things know how to update it.
struct RouteEncoder: Encoder {
var components: Box<[String]>
//...
}
struct RouteDecoder:Decoder {
var components: Box<[String]>
//...
}
final class Box<Value> {
var value: Value
init(_ value: Value) {
self.value = value
}
}
The second more complex approach would be to create some kind of CustomDataNode like structure that can handle insertions into a nested hierarchy which may or may not transform any of the data types. This works better for more complex data or generalized implementations that potentially need more runtime customization. A separate serialization service also gets created that can take in an instance of the CustomDataNode type and produce the desired final output type. This could look something like:
//-------------------------------- PSUEDO CODE ---------------------------------
struct PublicEncoderType {
func encode(value:Encodable) -> String {
let encoder = _PrivateEncoderType()
let encodedValue = try encoder.encodeAsDataNode(value)
//sometimes the serializer is passed into the encoder.
let serializer = (some SerializerProtocol)()
return try serializer.createString(encodedValue)
}
}
//Sometimes inside the above class, sometimes not.
class _PrivateEncoderType:Encoder {
var data = MyDataNode
func encodeAsDataNode(value:Encodable) -> MyDataNode {
//Serious fanciness ensues to update data.
return data
}
//...other things
}
//Sometimes inside one of the above classes, sometimes not.
enum MyDataNode {
case value(String)
internal case array([value])
internal case object([String:value])
}
protocol SerializerProtocol {
//fanciness to get the data -> the desired output.
func createString(MyDataNode) -> String
}
With the explicitly two step process some harder decisions have to be made about what is “Encoding” and what is “Serialization.” Lets look at the example of a Date. If the Encoder will override a Codable value’s default transformation, it has to catch it somewhere.
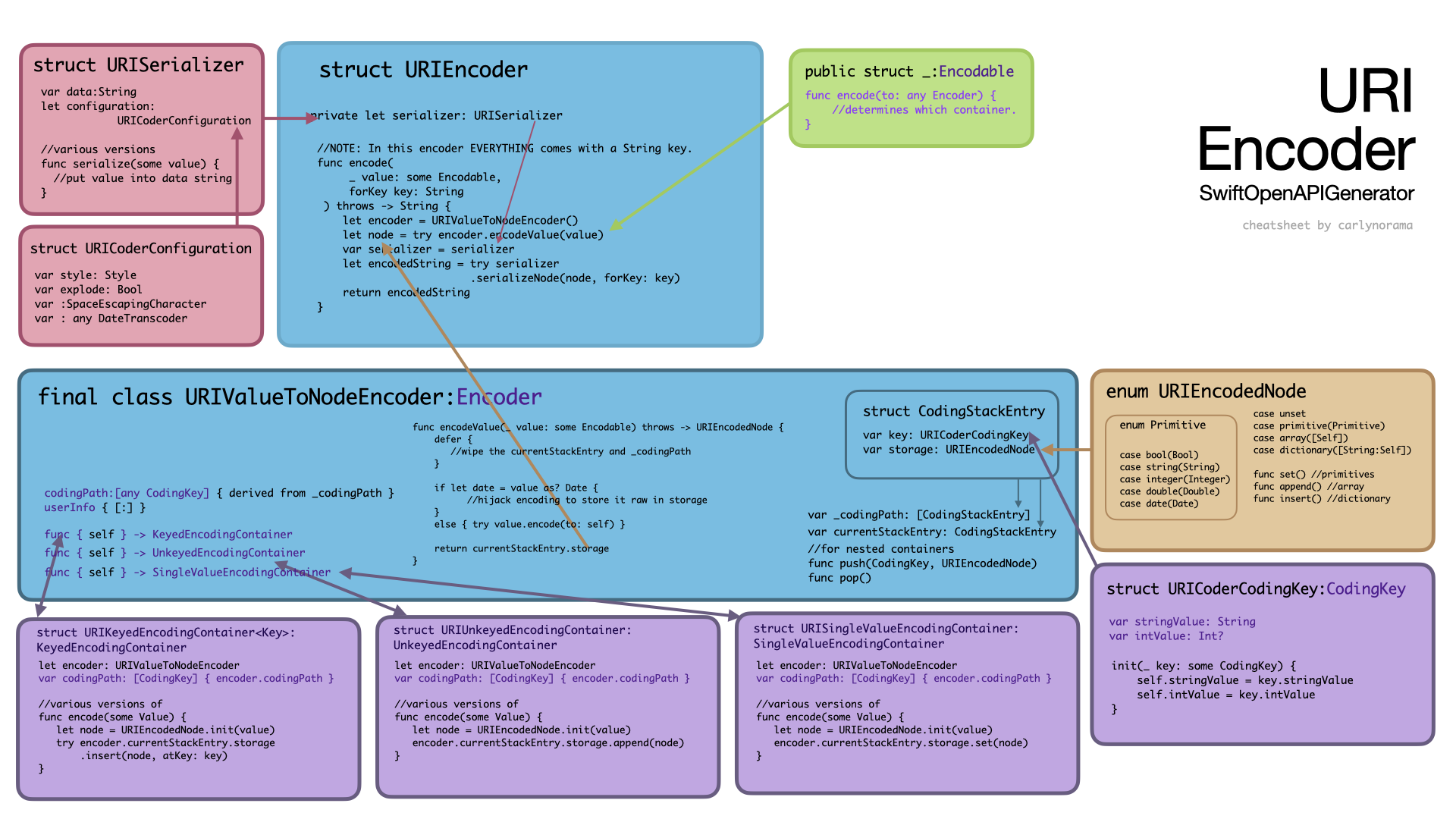
In the URIEncoder a Date gets held in the URIEncodedNode as a Date. A [URISerializer][serializer] instance, configured with a DateTranscoder, gets passed to the Encoder on initialization. This serializer then handles all the -> String behaviors. The URIEncodedNode catches the Date before it can be stringified by its own Encodableyness right in the main encodeValue(some Encodable) function.
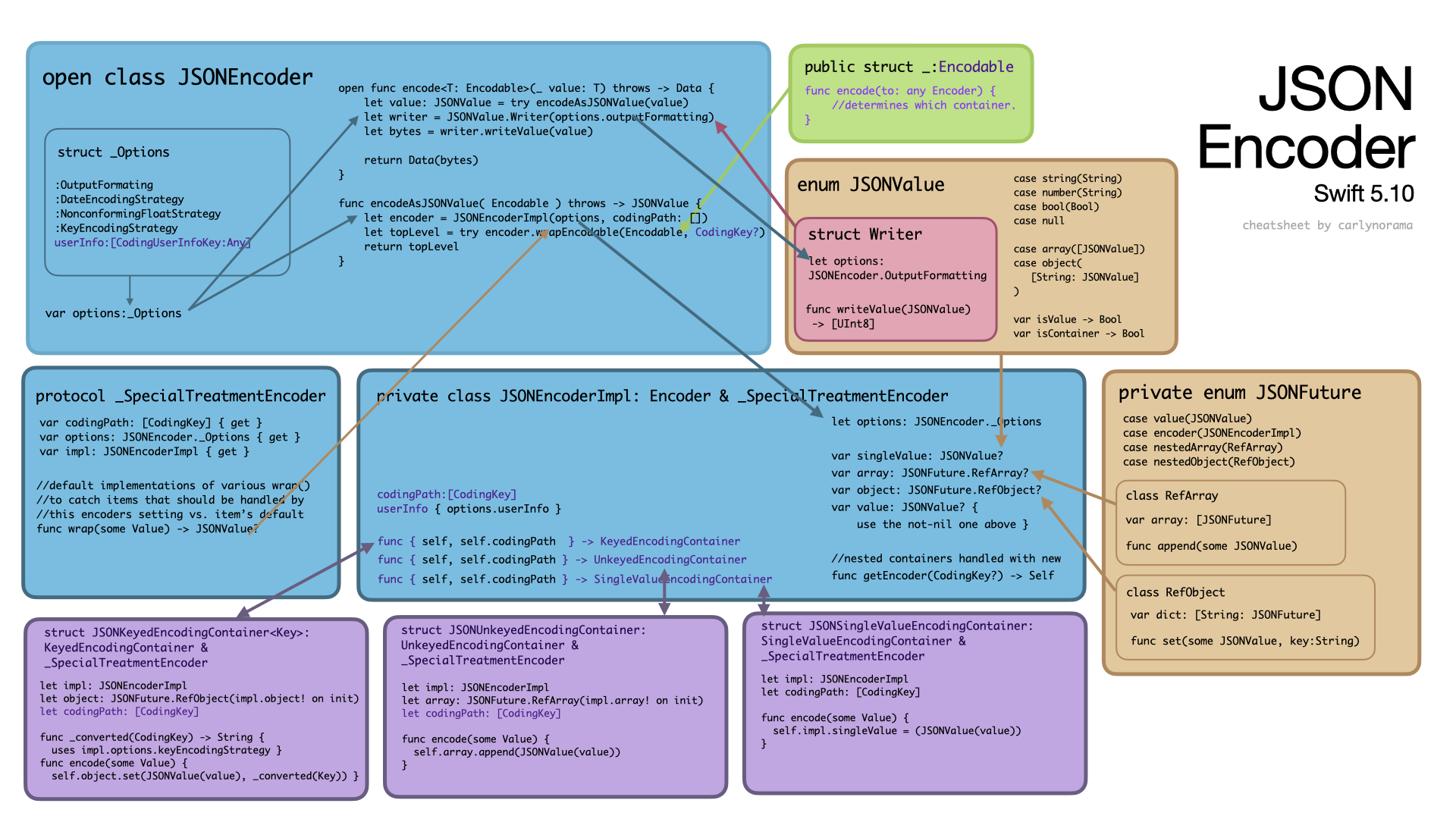
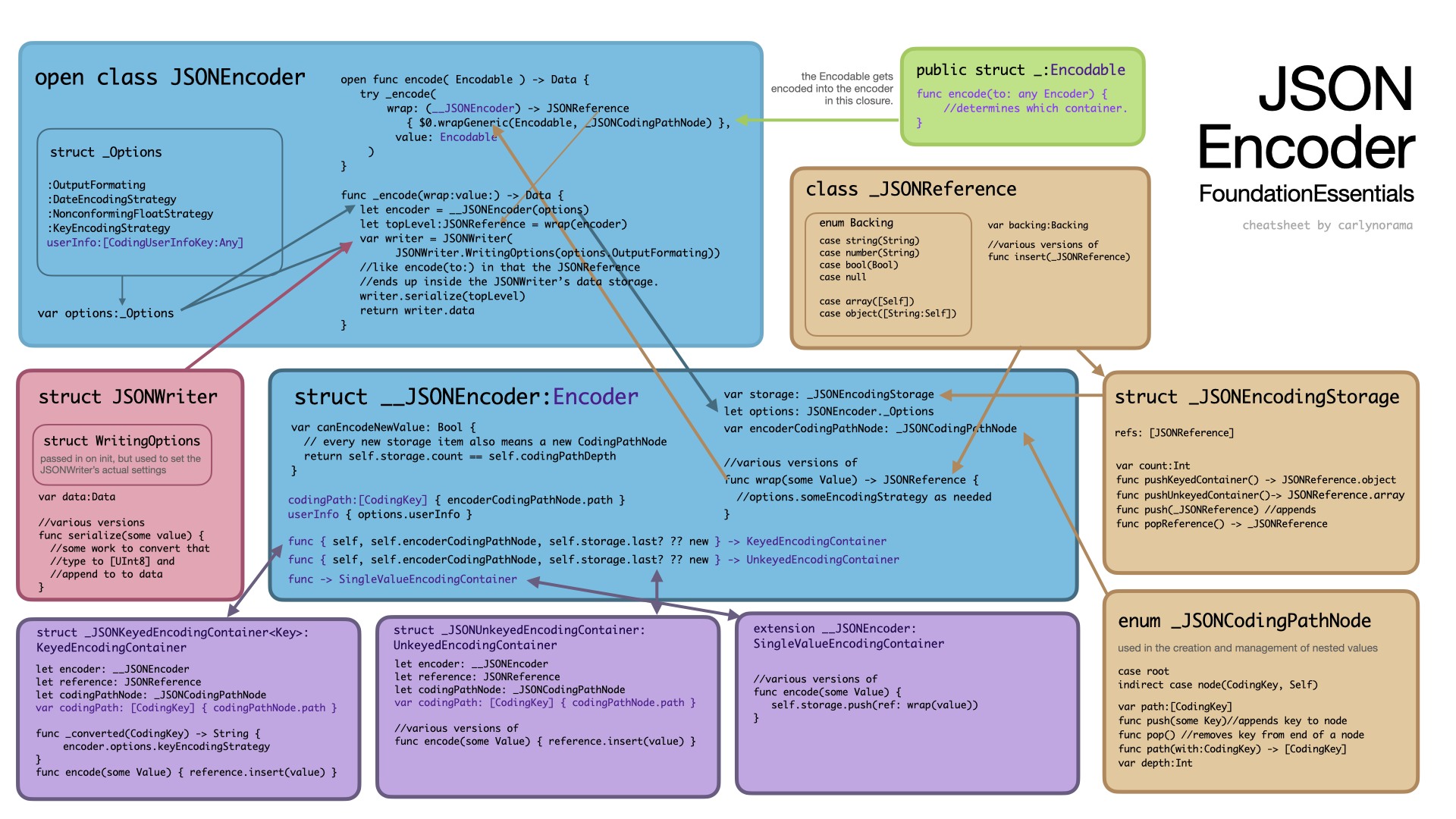
In both the JSONEncoders, a Date gets turned into a String by the Encoder in a function that uses the DateEncodingStrategy to determine the format before it even hits the JSONFuture/JSONReference data storage types of the 5.10 version and the FoundationEssential version respectively. The serializer in the JSONEncoders is called a writer. In the 5.10 version it’s attached as extension to backing storage type of a JSONFuture, a JSONValue. In the FoundationEssentials version it’s a standalone JSONWriter. Both writers take configuration values for other things, but the date strategy belongs to the Encoders not the Writers. The function that intercepts the Date lives in a _SpecialTreatmentEncoder protocol for the 5.10 JSONEncoder. That protocol gets applied to just about everything. In the FoundationEssentials version those “wrap” functions live in the Encoder implementation which gets passed around.
The http-structured-headers StructuredFieldValue approach instead restrains the inputs. It requires all values submitted to the top level public encode function to conform to a protocol with the single requirement of an enum value that can tell the Encoder if it’s a single value item, array or object. To shorten what’s actually a longer story, the backing storage won’t even accept a Date. An allowed BareItem must already be a Bool, Int or predigested into a specialized String. A Date couldn’t even get that far without throwing an error. Additionally, since this package has a very constrained output type it provides a single lightweight non-customizable serializer struct that gets initialized on demand in several places.
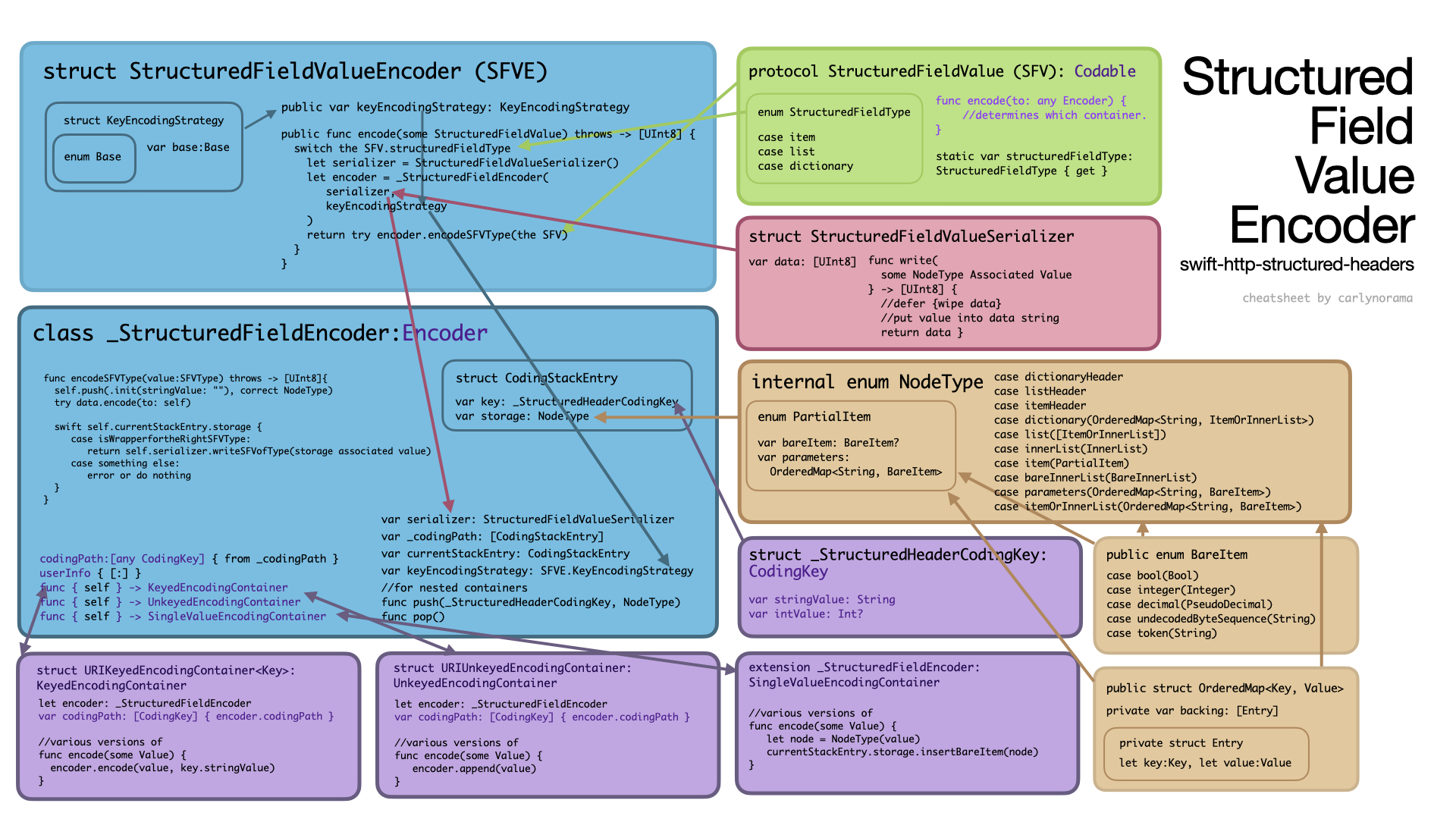
Encoding Containers
So what entities even make the calls to update the data store? Lets pull out the Encoder protocol:
public protocol Encoder {
/// The path of coding keys taken to get to this point in encoding.
var codingPath: [any CodingKey] { get }
/// Any contextual information set by the user for encoding.
var userInfo: [CodingUserInfoKey: Any] { get }
/// Returns an encoding container appropriate for holding multiple values
/// keyed by the given key type.
/// ... (e.g. Structs, Classes, Dicts)
func container<Key>(keyedBy type: Key.Type) -> KeyedEncodingContainer<Key>
/// Returns an encoding container appropriate for holding multiple unkeyed
/// values.
///... (e.g. Arrays)
func unkeyedContainer() -> any UnkeyedEncodingContainer
/// Returns an encoding container appropriate for holding a single primitive
/// value.
///... (Bare primitives)
func singleValueContainer() -> any SingleValueEncodingContainer
}
The container function returns a concrete KeyedEncodingContainer<Key> whose initializer wraps the developer’s own implementation of the KeyedEncodingContainerProtocol. The other two allow for just returning a protocol conforming type directly.
In the diagrams above they’re the purple boxes on the bottom.
Sometimes a developer’s implementation of these protocols
- extends an
Encoderdirectly - gets passed an
Encoderto use - gets passed a reference to the data storage object that the active
Encoderis using.
All of these approaches work to enable these “Encoding Containers” to squirrel the submitted values into the appropriate data store. Note that something somewhere has to be a reference type so it can persist through multiple passes of the encoding process.
The encoding containers route the encoding process via nearly identical lists of functions which help the developer make sure they have thought of everything a generic Encodable item could throw at it. Examples include:
mutating func encodeNil() throwsmutating func encode(_ value: Bool) throwsmutating func encodeIfPresent(_ value: Bool?, forKey key: Key) throwsmutating func encode(_ value: Int64) throwsmutating func encode<T: Encodable>(_ value: T) throws- etc.
If a custom Encoder limits the types of values it can take in, it’s possible to get away with only adding valid implementations to a subset of the functions, but most of them still have to be there.
Handling CodingKeys
Developers also have to decide where and when CodingKeys get handled. The documentation simply states that a CodingKey is “a type that can be used as a key for encoding and decoding”. I did not find that particularly illuminating. Essentially, the CodingKey can store the name of the struct or parameter or whatever custom thing the person conforming their struct to Codable wanted it to be (example).
Conformance to Encoder and all of the encoding containers requires making a codingPath available, describable as a NavigationPath like array of CodingKeys.
var codingPath: [any CodingKey] { get }
Many implementations of encoding containers either set their codingPath to an empty array or set it to pull from a wrapped concrete Encoder directly. The objc.io example didn’t care about keys at all. It was making a URL based on values only. Some implementations leave it empty because the serializer only needs to know the key for the current level. Appending values to the path only becomes important if the serializer needs the full context to create appropriately formatted output along the lines of the StackOverflow example.
"StructA.StructB.StructC:43"
What even is the CodingKey type? It’s just a protocol that’s pretty darn easy to conform to:
//minimum viable CodingKey
internal struct MySpecialKey: CodingKey {
var stringValue: String
init?(stringValue: String) {
<#code#>
}
var intValue: Int?
init?(intValue: Int) {
<#code#>
}
}
However, just like with values, something has to do the transformation of the CodingKey into the Output type. The 5.10 JSONEncoder and some of the simpler types store the encoded information with the keys already turned into strings based on a strategy owned by the Encoder not the Writer.
public enum KeyEncodingStrategy : Sendable {
case useDefaultKeys
case convertToSnakeCase
case custom(@Sendable (_ codingPath: [CodingKey]) -> CodingKey)
}
In the container (_JSONKeyedEncodingContainer):
private func _converted(_ key: CodingKey) -> String {
switch encoder.options.keyEncodingStrategy {
case .useDefaultKeys:
return key.stringValue
case .convertToSnakeCase:
let newKeyString = JSONEncoder.KeyEncodingStrategy._convertToSnakeCase(key.stringValue)
return newKeyString
case .custom(let converter):
return converter(codingPathNode.path(with: key)).stringValue
}
}
Some of the more recently written encoders have a wrapping type which pairs the encoded value to CodingKey:
- the CodingStackEntry of StructuredFieldValue and URIEncoder
- the _JSONCodingPathNode of FoundationEssentials.
internal enum _JSONCodingPathNode {
case root
indirect case node(CodingKey, _JSONCodingPathNode)
var path : [CodingKey] {
switch self {
case .root:
return []
case let .node(key, parent):
return parent.path + [key]
}
}
//..more
}
final class URIValueToNodeEncoder {
struct CodingStackEntry {
var key: URICoderCodingKey
var storage: URIEncodedNode
}
///...
private var _codingPath: [CodingStackEntry]
var currentStackEntry: CodingStackEntry
init() {
self._codingPath = []
self.currentStackEntry = CodingStackEntry(key: .init(stringValue: ""), storage: .unset)
}
//...
}
extension URIValueToNodeEncoder: Encoder {
var codingPath: [any CodingKey] {
(_codingPath.dropFirst().map(\.key) + [currentStackEntry.key]).map { $0 as any CodingKey }
}
//...
}
These actually aren’t really for serializing the key values. They get used for handling nested encoders without creating new encoders. These three Encoder types also have push and pop functions to change their current encoding depth. The CodingKeys are still already stringified and sanitized before they’re inserted into the stored data objects and the serializer uses those values. This NodeType seems to be more about organizing nested containers than participating in the encoded key creation.
Summary
Encoders can be difficult to get started with because of the amount of flexibility they offer in terms of the approaches they’d support. Copying a few examples to understand how they work helped me a lot. Next post will cover a couple of implementation examples.
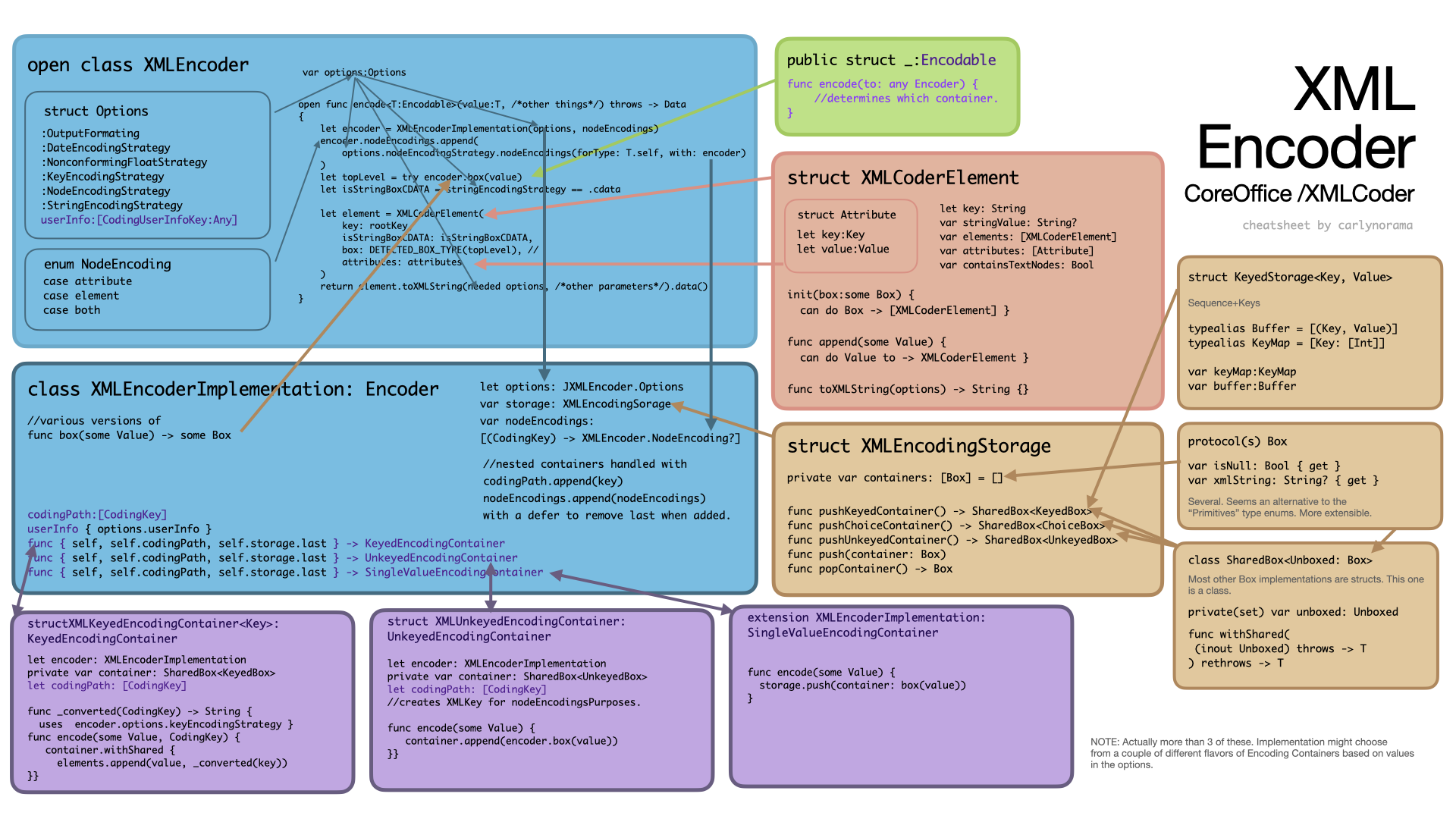
Epilogue - XMLCoder
One more Encoder to add to the stash. CoreOffice/XMLCoder
It uses a protocol instead of an enum to wrap all the possible values up in a format the serializer will know how to digest. A Date in this case would get caught and wrapped into a DateBox when it hit an encoder.box(value) step. That DateBox would likely be wrapped inside a SharedBox (the class type) and be placed inside the encoder’s storage array.
The XMLCoderElement initializers know how to unbox Box types and turn them into the correct XMLCoderElement configuration.
The XMLCoderElement felt like both serializer and storage so I made it a bit more orange than the other Serializers.
This article is part of a series.
- Part 1: What if I just copy-paste from the web?
- Part 2: How do you get messages to Swift directly?
- Part 3: Okay, but how about all the way up to the View?
- Part 4: How to do some basic file handling?
- Part 5: This Article
- Part 6: And what can I make a custom Encoder do?
- Part 7: Wait, how do I scan text again?
- Part 8: Date Parsing. Nose wrinkle.
- Part 9: What would be a very simple working Decoder?